Entwurf einer Theorie der Kopier-Praxis
kleine Nebenbemerkung: in den ganzen Debatten zum deutschen Kopierwesen bzw. Copycat-tum wird immer eines übersehen, nämlich dass sich in diesem Zuge paradoxerweise auch zunehmend die erste tatsächlich eigenständige deutsche Web-Theorie etabliert. Ich nenne sie in Anlehnung an Bourdieu einmal Entwurf einer Theorie der Kopier-Praxis.
Wann immer das Thema die Deutschen und ihre Klone von einem grösseren US-Blog aufgegriffen wird, dann poppen auch die Reaktionen auf, die sagen: stimmt ja nicht, das ist eigentlich ziemlich innovativ und gut, was wir hier machen.
Unlängst etwa Matt Marshall mit The German start-up scene: Copycats, but getting smarter (via) und als Reaktion Peter Schüpbach (übrigens ansonsten keiner der aggressiv/pragmatischen Kloner) mit Copycat – oder ‘act local’, aber es gibt eine ganze Reihe solcher Threads, deutsche startups oder gründerszene hatten einmal sogar eine ganze Serie mit Anleitungen zum richtigen Kopieren.
Das interessante an dieser sich abzeichnenden Theorie ist, dass sie mehr oder weniger vollständig ist, nur dass einige Begrifflichkeiten wie Ideen, Innovation, Kreativität, etc. aufgehoben aber dennoch in einer Art euphemistischer second order Reinterpretation wieder zurückgeschleust werden. Die eigene Idee zu einem Microblogging-Dienst, bei dem man max. 140 zeichige Nachrichten schreiben kann, kann einem durchaus während der Verwendung von Twitter kommen, mit einem Mechanical Turk Klon kann man durchaus auch staatliche Innovationspreise einheimsen, usw.
(dieser ansatz ist natürlich nur einer unter vielen. was wohl stimmt ist, dass es in deutschland tatsächlich keine grossen entwürfe zur zukunft des web gibt, nichts, was das gesamte milieu verändert, aber zu behaupten es gebe keine innovationen ist natürlich ein blödsinn. und auch bei den pragmatischen kopierkatzen gibt es viele, die ohne wahrnehmungsverschiebung auskommen und einfach die deutschen tugenden betonen bzw. den wert auf die ausführung und in der folge das community-building usw. legen. aber systemtheoretisch ist die copycat-theorie interessanter, weil sie die systemische komplexität reduzieren, indem sie ihre umweltsensoren minimieren, etc.)
Recht Recht Recht
Mir persönlich ist das Thema zwar eher egal, ich kaufe mir auch gerne die Bücher und Platten und DVDs, die ich wirklich haben will, die ganzen Filesharing-Dienste und Darknets kenn ich nur vom Hörensagen, auch die ganzen Pros und Cons krieg ich nur peripher mit, aber ein paar Punkte als Reaktion auf wiederkehrende Themen als Milchmädchenrechnung:
Die aktuelle Gesetzgebung bewirkt die grösste Verhinderung der Erzeugung von kulturellem Wert und den grössten Wohlfahrtsverlust, den es jemals gegeben hat.
Als Menschheit sind wir das erste Mal in der – vor 10 Jahren noch völlig undenkbaren – Situation, dass einerseits jeder – digital divide aside – potentiell Zugang zu jedem bis dato erzeugten Kulturprodukt haben könnte. Jeder Gedanke, jeder Groove, jeder Take aus jedem Film der jemals gedacht, gespielt, gedreht wurde, und alles andere könnte potentiell jedem, der Zugang zum Internet hat, zugänglich sein. (Leicht zugänglich gemacht wird im übrigen nur, was verblödet.)
Und nicht nur zugänglich, es könnte auch Ausgangspunkt für Weiterverarbeitung in Form von Mashups, Remixes, Samples, whatever sein, weil wir auch das erste Mal mit jedem PC/Mac/und Linux sowieso gleich mitgelieferte oder webbasierte Tools haben, mit denen wir diesen digitalen Content weiterverarbeiten können. Egal jetzt, ob wir einen Track als Hintergrundmusik für Fotos verwenden, die wir der Oma zeigen, oder die Rede eines Politikers arselectronicatauglich dekonstruieren, oder Samples verschiedener Quellen zu einem Mashup rekombinieren. Wir könnten mit allem spielen, und wir könnten die Ergebnisse davon wiederum in den kollektiven Gesamtoutput zurückführen.
Betonung liegt auf könnte, weil es eben die Einschränkungen gibt, die zuvor vorwiegend distributionstechnisch bedingt waren, jetzt aber rein verwertungsrechtlich sind. Die gesellschaftlichen, sozialen, kulturellen Opportunitätskosten, die dadurch entstehen, sind jenseits jeglicher Vorstellungskraft.
Diebstahl
Was man auch oft hört, ist, dass wir Diebstahl von geistigem Eigentum sehen, der die Produzenten um ihren verdienten Lohn bringen – und mittelfristig dazu führen wird, dass die kulturellen Güter schlicht nicht mehr erzeugt werden.
Aber zumindest in meinem naiven Verständnis hat Diebstahl eher mit einem Wegnehmen zu tun. Ich nehm es mir und ein anderer hat es dann nicht mehr. Ich hab dann einen Vorteil, der andere einen Nachteil.
Der Zugang zu einer digitalen Kopie nimmt niemandem etwas weg. Ich hab zwar auch plötzlich Zugang zu den gleichen Daten, aber ich habe dem Besitzer nichts weggenommen. Er hat es immer noch.
Andere Rechte regeln natürlich, dass ich das trotzdem nicht darf, aber die Konnotationen von Diebstahl greifen bei digitalen Gütern nicht.
Das andere was gegen das Gefühl eines Diebstahls spricht ist die Omnipräsenz von den zwei Problemkindern Musik und Film. Sie sind ohnehin überall. Wenn man den Fernseher anschaltet oder das Radiio anmacht strömen sie auf dutzenden frei wählbaren Kanälen auf uns ein, und auch im Web gibt es unzählige legale Dienste.
Revised
Web 2.0 is ultimately about understanding the rules of business in the network era.
…
Harvest every bit of user contribution, not just the explicit. Your business has thousands of touch points with customers. When they buy from you, they contribute data as well as money. When your suppliers increase their prices, or change their delivery times, they contribute data to you. When you advertise, and people respond (or don’t), they contribute to you. When you introduce a new product, when you do something your customers love, or hate, and people talk about it, they contribute.
…
It’s no longer good enough to gather data and analyze it, then propose and adjust strategies over the next budget cycle. You must infuse your organization with IT, so that, like Walmart, your supply chain responds every time a customer rings up an item at the cash register. This is how Walmart is like Google. No, not the website, but the live enterprise, which learns and responds.
…
Web 2.0 thrives on network effects (also known as virtuous circles): data begetting more data, services getting better in such a way that they are used more often, until you are so far ahead of the next guy that he can’t catch up.
Tim O’Reilly’s revised definition vom Web 2.0 (weg vom technokratischen (compact 1, 2005), weg vom neoglobalistischen (compact 2, 2006), hin zum datahamsterhegemonialen) ((natürlich hat er recht, aber die begriffsbestimmung wird tatsächlich immer dünner, je weiter sie sich von der kulturellen informiertheit – nicht dem mitmachdings oder dem überbau der demokratischen gutheit usw. – entfernt. as is ist es im grunde wirklich nur mehr auf die walmart’schen cash registers und die anschlussprozesse zusammengekocht, und das kann es ja auch nicht sein))
Show Off!

Blogger sozialisiert sich, wirft Followers ins Gemisch (Blogger.com Blogger können Blogger.com Blogs followen, gefollowte Blogger.com Blogs können die Followerschaft anzeigen, in Blogger gibt’s eine Reading List mit den gefollowten Blogs und auch in Google Reader ist das integriert)
Meine standard ‘Google, du sozialer Tolpatsch’ Predigt spare ich mir, aber interessant dabei ist, dass Google hier deutlicher als sonst den Fokus auf eine inzestuöse Selbstbefruchtung legt (beteiligt sind Blogger.com, Google Reader, bald Friend Connect) und damit eine Disposition offenbart, die man sonst eher MS, Yahoo, Apple zuschreibt.
Dolce and Gabbana
systemtheoretisch ist FriendFeed nicht uninteressant, weil es tatsächlich das autopoietische Reproduktionsorgan der us-tech-Blogosphäre wurde und also ebendiese das erste Mal in ein System proper transformiert. Nebeneffekt ist aber eine veränderte Form der Ausdifferenzierung, die sich zunehmend überhaupt nur mehr rekursiv auf sich selbst bezieht (ff als ort wo man sich zu sich selbst gratuliert) etc. (wenn man will könnte man frei nach d/g twitter als molekulare kraft beschreiben, die den diskurs deterritorialisiert, und friendfeed als molare, die reterritorialisiert)
((müsste man mal durchdenken, sind leider schon alle tot))
ReQuoting pt. 22
… when I am deep in search for knowledge on the web, jumping from link to link, reading deeply in one moment, skimming hundreds of links the next, when I am pulling back to formulate and reformulate queries and devouring new connections as quickly as Google and the Web can serve them up, when I am performing bricolage in real time over the course of hours, I am “feeling” my brain light up, I and “feeling” like I’m getting smarter. A lot smarter, and in a way that only a human can be smarter
john battelle via jurij m lotman zum neuen nick carr rant ob uns google dumm macht
(die frage an sich ist ein blödsinn, aber schief von oben betrachtet ist ganz witzig, dass carr in seinem text genau das macht, was battelle als gegenargument für sich beansprucht. gerade carr macht so eine art echtzeit-bricolage von statements, die miteinander nichts zu tun haben und die über non sequiturs miteinander verbunden sind, die aber den carr-geneigten lesern das gefühl des schlauerwerdens geben usw. trotzdem hat carr (google macht uns dumm weil wir uns selbst zur artificial intelligence degradieren) gwm. mehr recht als battelle (google macht uns schlau, frag nur die 80er jahre poststrukturalisten), nur geht er nicht weit genug. die eigentliche google-lesson müsste sein, dass wir erst via google sehen, dass unsere intelligenz nie authentisch sondern immer schon eine artificial artificial intelligence (mechanical turk) war usw.)
Überall Probleme
Das Problem mit Web 2.0 war, dass es keine Web 2.0 Group gegeben hat. (im grunde hätte schon eine puppe mit einem o’reilly kopf drauf, die den kopf schüttelt und mit dem finger auf die kompakt-definition zeigt, gereicht, ggf. noch mit einem formular zum beitreten)
Das Problem mit data portability ist, dass es eine Data Portability Group gibt. (man muss zwar fairerweise dazusagen, dass sie einen wirklich guten job dabei machen, die beteiligten konzepte zu sichten und zu erklären, aber der ganze komplex politik, pr und hegemonie über die begrifflichkeit beginnt zunehmend kontraproduktiv zu werden und etwas zwietracht unter den weniger oder nicht beteiligten parteien zu stiften. data portability (der intuitiv verständliche begriff, der wunsch nach, die praxis der, …) ist etwas, dessen zeit einfach gekommen ist. aber nicht wegen der oder durch die data portability group, die war nur sehr geschickt dabei, den begriff rechtzeitig zu besetzen, pro-forma allianzen mit allen grossen spielern zu schliessen, die werbetrommel zu rühren und erfolge für sich zu verbuchen, wobei ich da nicht wirklich einschätzen kann, inwieweit sie das selbst forciert haben, oder halt die berichterstattung nur nicht aktiv verhindert bzw. richtiggestellt haben. wie auch immer, an der dpg ist gut, dass koordiniert über die ganzen themen nachgedacht wird, aber die namenskollision mit einem generischen begriff ist etwas unglücklich und dafür prädestiniert, verwirrung zu stiften)
ReQuoting pt. 20
The idea of building competitors to Twitter on the same platform, or redistributing Twitter to multiple players reminds me of the idea that New York City should be rebuilt in Ohio because it would be cheaper. Or perhaps we could distribute a little of New York City in every state of the Union. New York City is what it is because of the people who live and visit there. Building another New York City in Las Vegas doesn’t result in the phenomenon that is New York City. In a very important sense, Twitter is decentralized at its core, it is rhizomatic rather than arborescent.
echovar via winer über die Gilmor Gang Idee Twitter zu föderalisieren.
(die architekturmetapher scheint insgesamt sehr nützlich als reality check für alle reflexartig angedachten verbesserungen in form von open-(source|id|social|portability|…), die es zu so ziemlich jeder populäreren seite bzw. phänomen zur genüge gibt, die aber meist floppen, einfach weil sie kein echtes problem lösen, das die anwohner haben, wenn die stadt funktional offen und attraktiv genug ist (del.icio.us vs. alle bookmarking clones, digg vs. alle pligg basierten digg clones, facebook vs. open social, etctrara). rein ideologisch getriebene offenheit, die sich nicht aufgrund einer eingebauter dna als (attraktive) stadt reterritorialisiert führt im besten fall zu einer bladerunnerschen dystopie und viel wahrscheinlicher zu endlosen vorstadtsiedlungen. google friend connect [war http://www.google.com/friendconnect/] etwa fördert eher wild durcheinanderwachsende soziale schräbergärten.)
ReQuoting pt. 18
regardless of where my content and data originate, I have a right to pull this data into MY sandbox, a sandbox where I track my threads, organize my media, filter my views and push my content wherever and however I please.
Mark Sigal via OYI [link tot]
(kein neues problem, natürlich, aber je disparater wir unsere inhalte sähen, desto drängender wird es. services die als strategie der kundenbindung unsere daten einkapseln und horten leben gwm. noch davon, dass der leidensdruck und das wissen um die möglichkeiten noch unterschiedlich verteilt sind)
((wenn man zynisch ist könnte man argumentieren, dass die zwangsbeglückende einkapselung so blöd nicht ist. aufgeklärte user ziehen weiter, und die die bleiben (weil sie noch nicht wissen was schon möglich ist oder bald möglich sein wird – völlig unwertend, weil nicht jeder 20 stunden in der woche im web verbringt und weil die informationsbeschaffungskosten bzgl. der möglichkeiten einfach sehr gross sind) sind auch die, mit denen man auch sonstigen schabernack treiben kann))
Katzencontent

Über die Startseite von FriendFeed freu ich mich jedes mal. Ich bin natürlich von einfachem Gemüt und Photos von Küken erheitern mich allemal, aber spannender finde ich fast die semiotische Souveränität die dabei zu spüren ist.
(einerseits das prinzip signifying wie wir es etwa aus dem hiphop / dem black english kennen, also der innerhalb einer gruppe stattfinden umbedeutung von ausserhalb der gruppe negativ konnotierten bezeichnungen für eben diese gruppe (nigga, bitch, usw.), im falle friendfeed also, dass sie genau das als selbstbeschreibung verwenden, was dem user generated web von den mainstreammedien als mangel angedichtet wird (wo steckt der qualitätsjournalismus wenn jemand ausdrückt was er denkt oder mit katzenphotos dokumentiert wie er lebt usw.) und andererseits die gwm. doppelte verdichtung des ausdifferenzierteren phänomens im einfacheren begriff (katzenkontent als superset eben jeglicher art von content bzw. als latentes ausdruckspotential) ohne noch viel dazusagen zu müssen)
((das dazusagenmüssen des sinns bzw. das glauben den sinn dazusagenzumüssen ist übrigens der beste indikator dafür, dass irgendwas nicht oder noch nicht funktioniert und verunmöglicht oft aber leider eben auch genau, dass es jemals funktionieren wird, weil dann oft die mischung nicht mehr stimmt, sich unfruchtbarere praktiken etablieren, usw.))
Querfinanz
Sowohl medienkonvergenz als auch zweinull klagen gerade ein bisschen darüber, dass Querfinanzierungen von Google und gieriges Kapital von VCs dem Web schaden, weil sie die Mentalität des Bezahlinix fördern. User haben sich angewöhnt im Web alles für lau zu erwarten, und das sei für das System ungesund und spiele nur den Grossen in die Hände. Ermöglicht werde diese Unart aber einerseits, weil dummes Venture Kapital Dienste subventioniert in der Hoffnung möglichst schnell möglichst viele User anzuhäufen, um es dann in letzter Sekunde bevor die Blase platzt noch schnell abstossen zu können, und andererseits durch Google et al., die die Geiz ist geil Mentalität fördern, indem sie alles kostenlos anbieten (“Quersubventionierungsmonster”), einfach weil sie es sich leisten können. Der monokulturalisierende Effekt sei aber, dass sie den Mittelstand und die Kleinen aus dem Rennen werfen, weil es schwer ist gegen dieses gratis zu konkurrieren.
Ay.
Im Grunde sind die ökonomischen Prinzipien im Web sehr einfach: ein Angebot muss – will es mittelfristig und autonom bestehen – zwei Dinge tun: Wert erzeugen und Teile des Werts irgendwie monetarisieren. Wert entsteht an unterschiedlichen Stellen. Als Individualwert (der Wert den ein Nutzer für sich selbst aus der Benutzung zieht), als Sozialwert (der Wert der für Benutzer dadurch entsteht, dass auch andere – Bekannte oder interessante Unbekannte – mitmachen), als Systemwert (der Wert für den Anbieter der dadurch entsteht, dass alle zusammen mitmachen) oder auch als Gesellschaftswert (was hat die Welt wie sie ist davon, dass es das Angebot gibt).
Eine mögliche Form der Monetarisierung ist natürlich, die Nutzer für die Benutzung bezahlen zu lassen. Sie ziehen ja einen Nutzen, warum sollen sie nicht auch dafür bezahlen? Andreas und Martin sind sich einig, dass das der erstrebenswerte (und der einzige nachhaltige) Mechanismus ist, um ein gesundes Ökosystem an Webanwendungen und Inhalten und Webanwendungsmachern und Inhalteproduzenten zu gewährleisten.
Für Anwendungen die hohen Individualwert aber wenig Sozial- und Systemwert erzeugen macht das ev. auch Sinn. Paradigmatisches Beispiel ist das Produktportfolio von 37signals. Man kann seine Kontakte auf vielerlei Arten verwalten, aber Highrise macht das einfacher und effektiver, man spart Zeit und also Geld, dafür bezahlt man gerne. (Solche Anwendungen sind oft zwar webbasiert, aber nicht webnativ; es könnte sie etwa auch als Desktop Anwendung geben, aber es ist halt nützlich auf sie von überall aus zugreifen zu können, etc.)
Für Anwendungen die aber primär Sozial- und Systemwert erzeugen (dass sie Individualwert erzeugen ist eine Voraussetzung, sonst würden sie einfach nicht benutzt) ergeben sich aber interessantere – und dem Web eigene – Möglichkeiten. Natürlich könnte man auch hier versuchen Geld zu verlangen, aber wäre es nicht schlauer die Anstrengungen darauf auszurichten, eher die Eintrittskosten gering zu halten um den Sozialwert und den Systemwert zu maximieren und dann ein Modell zu finden, diese zu vergolden?
Wert ist im Web kein Nullsummenspiel und die Kosten, die ein neuer User verursacht, gehen gegen null.
Den Systemwert zu maximieren bedeutet nicht möglichst schnell möglichst viele User heranzukarren und Monetarisieren nicht notwendigerweise diese dann auf möglichst viele Ads klicken zu lassen. Aber Kosten schrecken nun mal User ab (und das hat nicht notwendigerweise nur mit Pfennigfuchserei zu tun, oft sieht man etwa Modelle, bei denen man sich in eine (doch eher zu vermeidende) langfristige Abhängigkeit zum jeweiligen Dienst begibt, weil die eigenen Daten nur solange zugänglich sind, solange man auch bezahlt, man denke an flickr) aber der Systemwert wächst (bei Anwendungen die die Dynamik richtig nutzen) mit jedem User exponentiell (egal jetzt ob im strengen Sinn exponentiell oder nicht, jedenfalls um ein vielfaches stärker als der Individualwert) – also ist gratis in den allermeisten Fällen Voraussetzung dafür Wertkreation an anderer Stelle stattfinden zu lassen.
Wenn Andreas und Martin argumentieren Google querfinanziere irgendwas übersehen sie, dass für Google alles Systemwert erzeugt und dass Google eben Möglichkeiten gefunden hat, Aktivitäten, die an einem auch noch so entlegenen Dienst stattfinden, an anderer Stelle zu Monetarisieren.
Um mich selbst zu zitieren
(der konzeptionelle Fehler der bei der Frage nach (und der impliziten Erwartung einer Antwort an) einem Geschäftsmodell wohl begangen wird ist, den Begriff auf dem Niveau einer buchhalterischen Monetarisierung zu beschränken und dabei zu übersehen, welche ökonomischen Strukturveränderungen mit gleichzeitiger Wertschöpfungsexplosion jenseits einer an Firmen gekoppelten Input/Output-Maschinerie stattfinden, welche Kanäle entstehen, die diese distribuieren, usw. – Strategien dazu etwa im Gesamtwerk von Bubblegeneration, oder praxistauglicher etwa bei Exciting Commerce)
Es ist lobenswert für die Kleinen und die Mittelständischen in den Ring zu springen, aber man hilft ihnen glaub ich nicht, indem man sich eine höhere Bezahlmentalität herbeiwünscht, wenn die Probleme die sie lösen von anderen schon besser gelöst sind oder leicht besser gelöst werden können oder wenn es überhaupt nur Scheinprobleme sind. (“Und ernsthaft, Protektionismus braucht keine Sau.” – neunetz)
Wird es ein Gemetzel unter den 20.000 aktuell aktiven (keine Hausnummer, es gibt wirklich mindestens so viele, alleine in Deutschland schon um die 1.500) Webanwendungen geben? Sicher. Noch viele mehr werden – weil die operativen Kosten oft aus dem Taschengeld bezahlt werden können – in Nieschen mehr oder weniger dahindümpeln, ja und? Und die Zukunft ist nicht düster (wie es Andreas und Martin skizzieren). Zwar gibt es für Startups kein Recht auf Erfolg, aber Startups haben mehr Chancen als je zuvor. Auch egal wenn nicht mehr als je zuvor, jedenfalls haben sie viele schon angedachte aber auf eine bessere Implementierung wartende und/oder noch unangedachte Chancen im Grossen wie im Kleinen, nur ändern sich diese und die Startups müssen ihr Skillsset an die Gegebenheiten anpassen (auch wenn es vielleicht gemein ist, dass Google und Co einige bisherige Möglichkeiten verunmöglichen.)
Gut für die, denen es gelingt dafür auch direkt bezahlt zu werden, aber viel besser für andere, die andere Wege der Monetarisierung erfinden bzw. diese systemisch einbauen – und noch viel besser für jene, die einen genuin neuen Wertvorschlag machen bzw. mit ineffektiven Wertschöpfungsketten brechen (paradigmatisch Etsy).
OpenPropagID
Chris Messina sinniert über die Implikationen der Ma.gnolia goes openID only Entscheidung (via, siehe dort auch)
(er reisst einige spannende aspekte an, openid’ifizierte ids etwa sind mehr oder weniger auch verifiziertere ids und erlauben uu. vertrauensvollere implizite empfehlungssysteme usw, aber ich werde das gefühl nicht los, dass die grundannahmen von fast allen grundsätzlichen überlegungen zu openid, identity 2.0, open social etc. einerseits aus der perspektive des geekischen, sich selbst überall, mit allen und am besten rekursiv propagierenden (woran üblicherweise bestimmte interessen und vorteile gekoppelt sind) und/oder mit endloser kommunikativer energie ausgestatteten individuums und andererseits aus der perspektive der mit zunehmendem appetit auf den globalen, in die cloud injizierten, maschinenlesbaren und am besten vollständigen social-graph-kuchen ausgestatteten seiten geworfen werden. ich will jetzt auch nicht raunzig oder reaktionär klingen, das ist alles super und wird sich mittelfristig ohnehin von alleine ausdifferenzieren)
Eine Minitheorie der Benutzung von Webapps
Gehen wir von einem rationalen Menschen aus. Wann wird er das Web im allgemeinen / eine konkrete Webanwendung im speziellen benutzen? Wenn die Benutzung ihm das Leben erleichtert, verbessert, irgendwas vereinfacht, beschleunigt, verbilligt, etc. Und er wird die Finger davon lassen, wenn es ihn nicht besser oder sogar schlechter stellt.
So trivial diese Annahme ist, mit ihr können einige Kritikpunkte entschärft und Verhaltensmuster bewertet werden.

Die zwei grundsätzlichen Fehlverhalten:
(a) das Web in einer Situation nicht zu verwenden, in der es geeignet wäre.
(b) das Web in einer Situation zu verwenden, in der man besser etwas anderes machen sollte.
Was sind die Voraussetzungen (man könnte das natürlich noch weiter differenzieren) dafür, das Web vernünftig einzusetzen?
(1) Kenntnis – man muss den geeigneten Webdienst kennen. Wer eine der Möglichkeiten des Webs nicht kennt, kann sie offensichtlicherweise auch nicht benutzen. Ein vernünftiger Benutzer sollte also die Augen offen halten, um am Laufenden zu bleiben, was es alles gibt.
(2) Urteilskraft – man muss die im Webdienst inhärenten Möglichkeiten sehen und verstehen können. Wer das Potential eines Dienstes nicht adäquat einschätzen kann, kann keine fundierte Entscheidung treffen, ob er die investierte Zeit Wert ist oder nicht.
(3) Kompetenz – man muss den jeweiligen Webdienst benutzen können. Mit der Kompetenz ist es so eine Sache. Es vergeht keine Woche, in der nicht mit Verve gefordert wird, die Dinge mögen einfacher werden, sonst wird das nix. So einfach, dass sie auch der dümmste versteht, etctrara.
Ich bin ein riesiger Fan der Einfachheit – aber: Ich weiss nicht woran es liegt, dass die an die Person stellbaren Anforderungen gegen Null gehen, sobald es ums Web geht. Menschen, die sich als durchaus überlebensfähig zeigen, wenn es ums Kochen, Autofahren, Gamen, oder Handwerken geht, werden ifantilisiert und sollen davor beschützt werden, einige fundamentale Techniken der Webbenutzung zu lernen. Wie in vielen anderen Situationen auch: ein paar Basics muss man können.
Prioritäten setzen
real estate für uservideos auf den startseiten von sevenload resp. youtube:

(sevenload: ~3,5%)

(youtube: ~42%)
The next readwriteweb
Einer der besten und einer der schwächsten Posts von R/WW innerhalb von 24 Stunden:
Distributed Mass Customization: Is Etsy the Next eBay? – wunderbare Aufbröselung der etsy ist das nächste google (was für ein bullshit) Diskussion (siehe auch)
Beware of Freeconomics – hingegen verpasst nicht nur elegant den Punkt um den es in der Freeconomics geht, sondern verwendet auch wahrscheinlich das blödest mögliche Beispiel das anzuprangern (gmail als powerplay eines monopolisten der es sich leisten kann die teuren bandwidthkosten herzuschenken um die konkurrenz in die knie zu zwingen und innovativen nachrückern von haus aus die motivation zu nehmen (siehe); das problem für yahoo und co ist nicht, dass sie plötzlich auf einnahmen verzichten müssen, die sie davor über die differenzierung in crappy free und paid premium erzielt haben, sondern dass für google alles – weil bei midas google alles mit allem zusammenhängt und weil alles mit google zusammenhängt – wert erzeugt, für sie aber nicht.)
Premium Pizza
Das Premium-Modell von Xing ist tatsächlich völlig verrückt. Es verunmöglicht 14,4 Billionen Beziehungen (400.000 premiumuser könnten alle 4 mio user kontaktieren vs. die restlichen 3,6 mio simpleuser können das nicht, auch nicht nach facetten suchen, nicht einsehen wer auf ihrem profil war, etc.).
Xing überlegt sich nicht, wie es den grösstmöglichen Netzwerkwert und/oder Nutzen für seine User erzeugen kann, sondern welche Features es beschneiden kann, um die grösstmögliche Zahl zum kostenpflichtigen Premiumstatus zu treiben. Dass sie dabei Features amputieren die unmittelbar den Systemgesamtwert tangieren ist absurd.
(es geht nicht darum, dass ihnen der erfolg recht gibt. sie nützen halt den quasimonopolstatus in dem segment in deutschland aus. auch nicht darum, dass es unanständig wäre nach features zu diskriminieren und für einige davon dann geld zu verlangen. auch nicht darum, dass die premiummitgliedschaft den spreu vom weizen der userbasis trennt. sondern darum, dass xing den hebel dafür an der netzökonomisch dümmsten stelle ansetzt. als zahlender user würde ich mich nicht darüber freuen, dass ich strukturiert suchen kann, sondern mich eher darüber ärgern, dass ich von 90% nicht gefunden werden kann)
Statement of the obvious für alle startups und grownups:
- verschenkt, erleichtert und fördert alles was den Wert des Netzwerks steigert, was sinnvolle Verbindingen zwischen Usern herstellt, was Impulse/Aufmerksamkeiten strömen lässt.
- macht das Geld mit Features mit hohem individuellen Nutzen, der aber den Netzwerknutzen und die Systemdynamik nicht betrifft.
(etwas fingerspitzengefühl ist auch hier gefragt, besser ist’s wenn man nicht zahlt, um knüppeln zu entgehen die einem sonst vor die beine geworfen werden, sondern wenn man weiß und schätzt wofür man bezahlt. man will passionate users und kein bauernfänger sein. es gibt viele viele möglichkeiten, auch wenn man ev. ein bisschen mehr nachdenken muss. think zeitersparnis, integration und sync mit standard tools, offline benützbarkeit, ad-free, etc.)
(bei Services ohne oder ohne starke soziale Komponente liegt die Sache etwas anders, 37signals etwa sind da als Orientierung wie man’s machen kann sicher zu empfehlen, mindmeister macht es imho auch sehr smart)
weekend google kuchen chart
Verteilung von Companyblogs von Betacompanies bzgl. deren Selbst- bzw. Fremdgehostetheit:

(wirklich useless – aber witzig, dass blogger/blogspot doch noch recht deutlich vor dem ohnehin überschätzten wordpress liegt. bei den selbstgehosteten hat wp die nase ziemlich sicher ziemlich weit vorn. und leider nur ein blog in der amazon cloud)
donnerstag google kuchen chart pt. 2
Verteilung von dt. Webapps (1000+) nach Anzahl an Bookmarks bei del.icio.us (die longtail ergänzung zu dem):
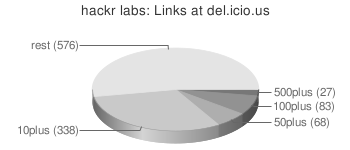
(düsteres bild eigentlich, zumindest kein indikator für ein florierendes bookmarkwesen und/oder ein breiter gestreutes interesse; mehr als die hälfte aller seiten hat weniger als 10 bookmarks, nicht mal 1/10 hat deren 100 oder mehr.)
(abt. weil die charts api so lustig ist)
donnerstag google kuchen chart
Verteilung von dt. Webapps (1000+) nach Anzahl von Blogreaktionen nach Technorati:



(düsteres bild eigentlich, zumindest kein indikator für einen florierenden diskurs und/oder ein breiter gestreutes interesse; etwa 1/3 aller seiten hat insgesamt 10 oder weniger erwähnungen in blogs, nur 1/4 hat deren 100 oder mehr und gerade mal 94 seiten haben mindestens 500 – wobei 20 blogs die ein tool 25x erwähnen auch schon 500 links für technorati generieren.)
Good Enough
They didn’t understand that you only need enough technology to make the product work.
…
Again, they have enough design (or the right design) to work for their users.
…
Pay attention … it’s important to understand that “accidental” isn’t the same as “random”. There are clues all around us, we just need to watch more closely.
Buchheit über was für neue Services wichtig ist (teilweise märchenstunde aber overall a good read) via langreiter
(aufmerksam zu sein ist übrigens was anderes als auf die user zu hören, das zu verwechseln ist einer der kardinalfehler von deutschen startups.)